
ResizeImage
先日 tbasic Ver.1.62を公開しました。今回,このバージョンに対応したプログラムを作ってみましたので,それを紹介します。
tbasicのVer.1.6での更新内容は主として,動作環境の整備でしたが,グラフ関係で
ResizeImageコマンド
も追加しました。このコマンドは,画像サイズの拡大縮小を行うコマンドです。また,Ver.1.61では,利用可能最大グラフ画面が4500×4500ピクセルになりました。また,Ver.1.62では,更にいくつかの機能の改良を行いました。
近年の携帯のカメラの高度化により,1200万画素も標準的ともいわれます。これはピクセルで言えば,4000×3000の解像度を意味します。このような状況に対応できるように,Ver.1.61では,最大4500×4500のグラフ画面を利用可能へと修正しました。これで,4032×3024の画像も扱えるようになります。
しかし,これらの画像は普通は数メガバイト以上のメモリを必要としており,メールに添付したりして利用するには大きすぎます。例えば,次の画像は,私のケータイで撮影したものですが,画面上は小さく見えますが,4160×3120ピクセルの画像で5.29Mバイトの容量を持ちます。

容量に余裕があれば,これをこのまま利用することも良いでしょう。しかし,場合によっては,メモリサイズをより小さくして,利用したいこともあるかもしれません。このような場合,画像サイズを小さくすれば,必要とするメモリも少なくなります。例えば,上の例でサイズを縦横4分の1にすると,1040×780ピクセルの画像でメモリは302Kバイトになります。これを以下に表示するとなります。このように表示すると見た目はあまり変わりませんが,画面サイズは1/16,メモリは1/17になりました。

このように,必要に応じて,画面の縮小ができると便利です。
画像1を画像2に変換する方法は色々あり,画像縮小ツールとしてwebで検索すれば多くのツールが見つかるでしょう。しかしここでは,tbasicを利用することを考えます。
(1) tbasicのプログラムを作成する。
tbasicでグラフ処理に慣れた人であれば,ResizeImageコマンドを利用して,プログラムは簡単に作成できます。それは,グラフ処理の定型的方法:「画像のロード」,「画像処理」,「画像の保存」での,「画像処理」の部分で,ResizeImage処理をするだけです。詳細な説明は避けますが,例えば,次のプログラムで可能です。
ChDir GetProgramDir
' プログラム,画像のあるフォルダをカレントディレクトリに設定
SI$="IMGSample.jpg" :' 入力画像名
TI$="IMGResize.jpg" :' 出力画像名
IMS$=GetImageSize$(SI$) :' 入力画像サイズの取得
WidthG =Val(Left$(IMS$,4)) :' 画像幅
HeightG =Val(Right$(IMS$,4)):' 画像高さ
GScreen(WidthG,HeightG,WidthG/4,HeightG/4)
' 画像用スクリーンの設定,表示は1/4画面を使う
LoadPicture(SI$)
GStretch On :' 全体を縮小して表示
ReSizeImage(1/4) :' 画像を縮小
SavePicture(TI$) :' 画像を保存
End
上のプログラムでは,画像1の名前がIMGSample.jpg,画像2の名前がIMGResize.jpgとしています。
これはこれで,実用上良いのですが,色々な画像に対して同様な処理を行うとすると,面倒と思うかもしれません。そこで,これらの処理を行う汎用的なプログラムを作ってみました。
(2) tbasic で画像縮小ツールを作成する。
このプログラムは全体で200行を超えるものですが,ReSizeImage.tbtという名前にしました。プログラムは以下にあります。(ファイルはzip圧縮されています。)
実は,このプログラムの動作には,tbasic 1.62以上が必要です。ResizeImageコマンドは,1.6でサポートされましたが,このプログラムでは,1.61,1.62で新たにサポートされた機能を使っています。
プログラムの骨格は上のものと本質的に同じですが,コントロール画面を利用したメニューを使って操作します。起動直後は次のようになります。
ここで,「読み込み」をクリックすると,
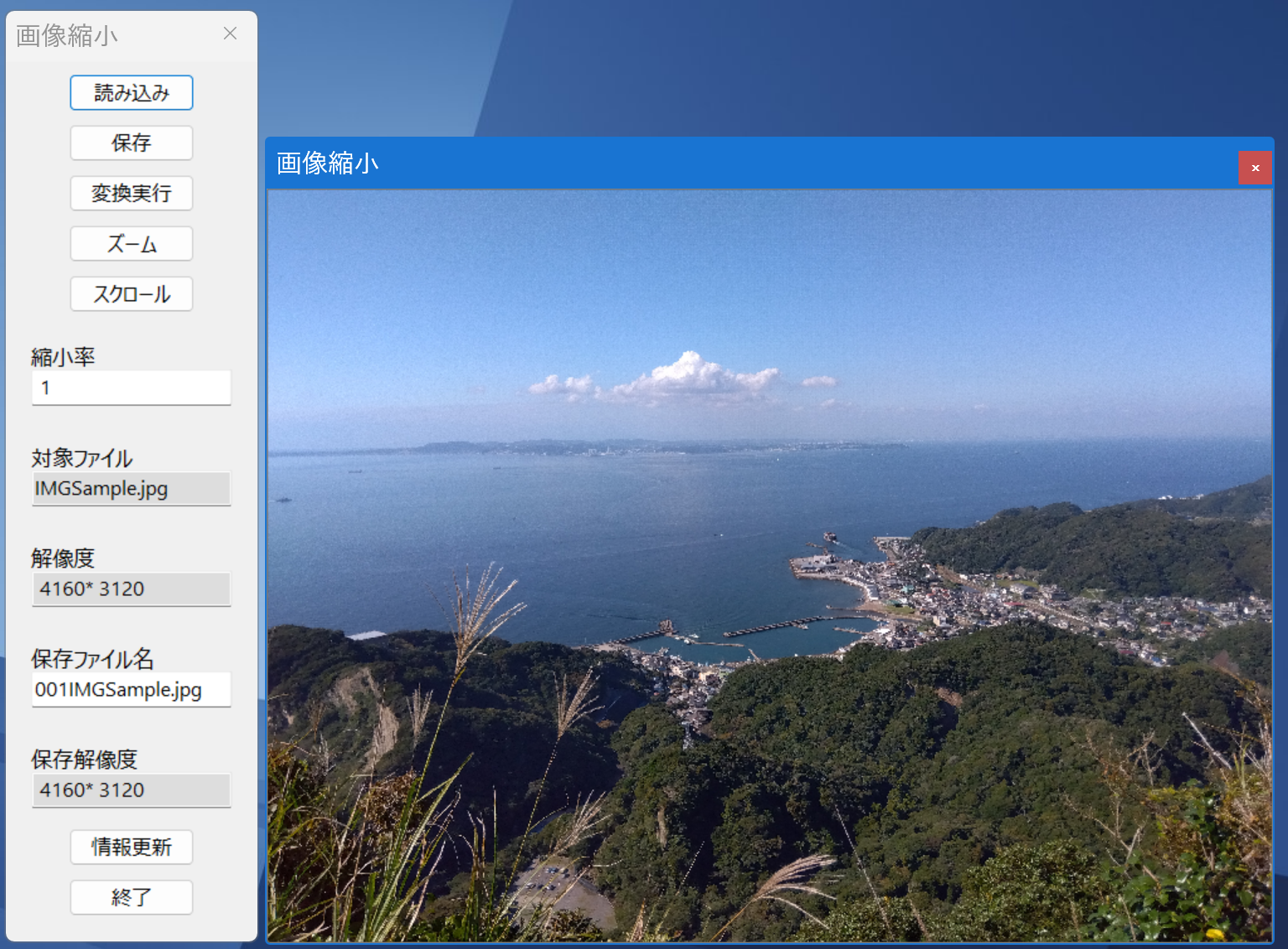
ダイアログが開き,対象とする画像を選択します。選択すると,画像の大きさを判定し,それに応じたグラフ画面が開かれます。大きな画像の場合は,800×800の画面を開き,縮小して表示します。画像1のファイルを選択した場合は,800×800の画面が開かれ,次のようになります。
この状態で,例えば1/4として,縮小率のボックスに1/4を入力して,Enterキーを押すと,メニュー部分が次のようになります。
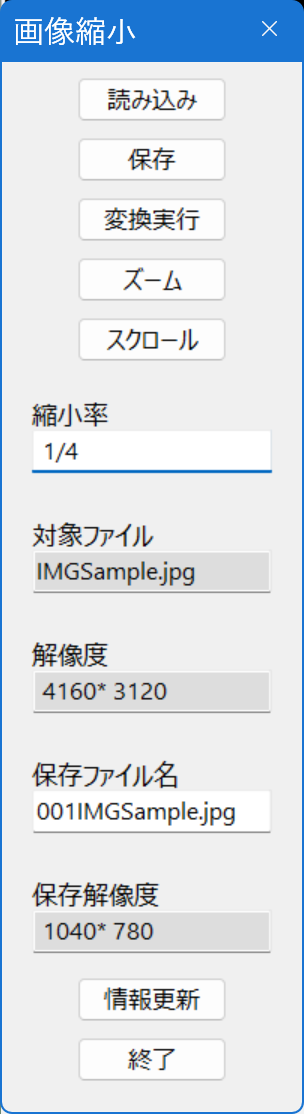
画像ファイルの解像度が,4160×3120ですが,縮小率1/4で縮小すると,解像度が1040×780になると示されています。
ここで,変換実行,保存とすることで,画像2のファイルが保存されます。プログラムは少し長いですが,一度作成すれば,色々な画像の縮小が簡単にできるので,使い道はあるのではと思います。